Jun 2026DatasetExpanded the Finch Collection with 71 additional optimization tasks (371 → 442) and 61,049 new trajectories (156,731 → 217,780).
Jun 2026TalkInvited talk at the AiDDA Conference 2026 (Virtual) — OpenEvolve Team Session.
May 2026OralEFT accepted as an Oral at the CAIS 2026 Workshop on AI Agents for Discovery in the Wild (AID‑Wild), with an invited talk in the OpenEvolve Team Demo Session (San Jose, CA).
TL;DR — Evolution Fine-Tuning (EFT) converts evolutionary search trajectories into supervision, giving small open-source LLMs a practice phase that teaches them how to evolve solutions before they ever see a new problem. Trained on the 156K-trajectory Finch Collection, our Finch models generalize discovery skill across 22 held-out tasks (+10.22% over base), compose strategies across domains, and reach state-of-the-art on circle-packing when paired with test-time RL.
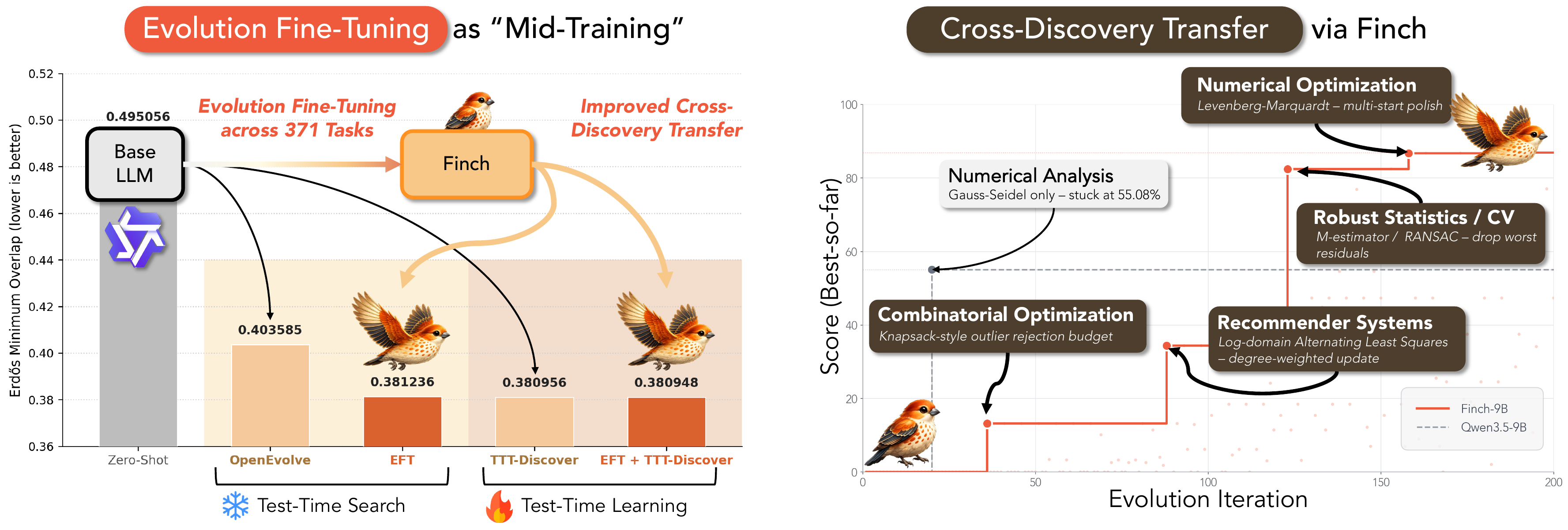
EFT acts as mid-training. Finch lifts discovery on the Erdős minimum-overlap problem under both test-time search and learning (left); on NP-hard competitive programming it composes strategies across domains, while the base model repeats a single one (right).
156K
filtered trajectories
371
tasks · 10 domains
+10.2%
avg. gain on 22 held-out
2–9B
Finch model sizes
Abstract
Would designing faster GPU kernels help close in on an open math conjecture?
LLMs integrated into evolutionary search have recently produced state-of-the-art solutions on optimization tasks — open mathematical conjectures, GPU kernel design, scientific-law discovery, and combinatorial puzzles. To achieve this, prior work applies a search scaffold to one target task at a time, so every new problem is approached from scratch and the experience accumulated during search is discarded once the model finishes. This leaves the capability of iteratively evolving a solution — knowing which part to mutate and how, deciding when to backtrack — entirely in the scaffold rather than in the model itself.
We introduce Evolution Fine-Tuning (EFT), a mid-training paradigm that teaches LLMs to evolve solutions across tasks by converting evolutionary search trajectories into supervision. We construct the Finch Collection, a 156K-trajectory dataset spanning 10 domains and 371 optimization tasks, and fine-tune open-source LLMs from 2B to 9B parameters. Empirically, EFT confers cross-task generalization: across 22 held-out tasks, our models surpass their base counterparts by 10.22% on average. Furthermore, when paired with test-time RL, our model matches state-of-the-art performance on two circle-packing tasks and outperforms its base-model counterparts on the Erdős minimum-overlap problem. EFT thus serves as a “practice phase” for general-purpose discovery agents that doesn’t solve new problems from scratch.
The idea
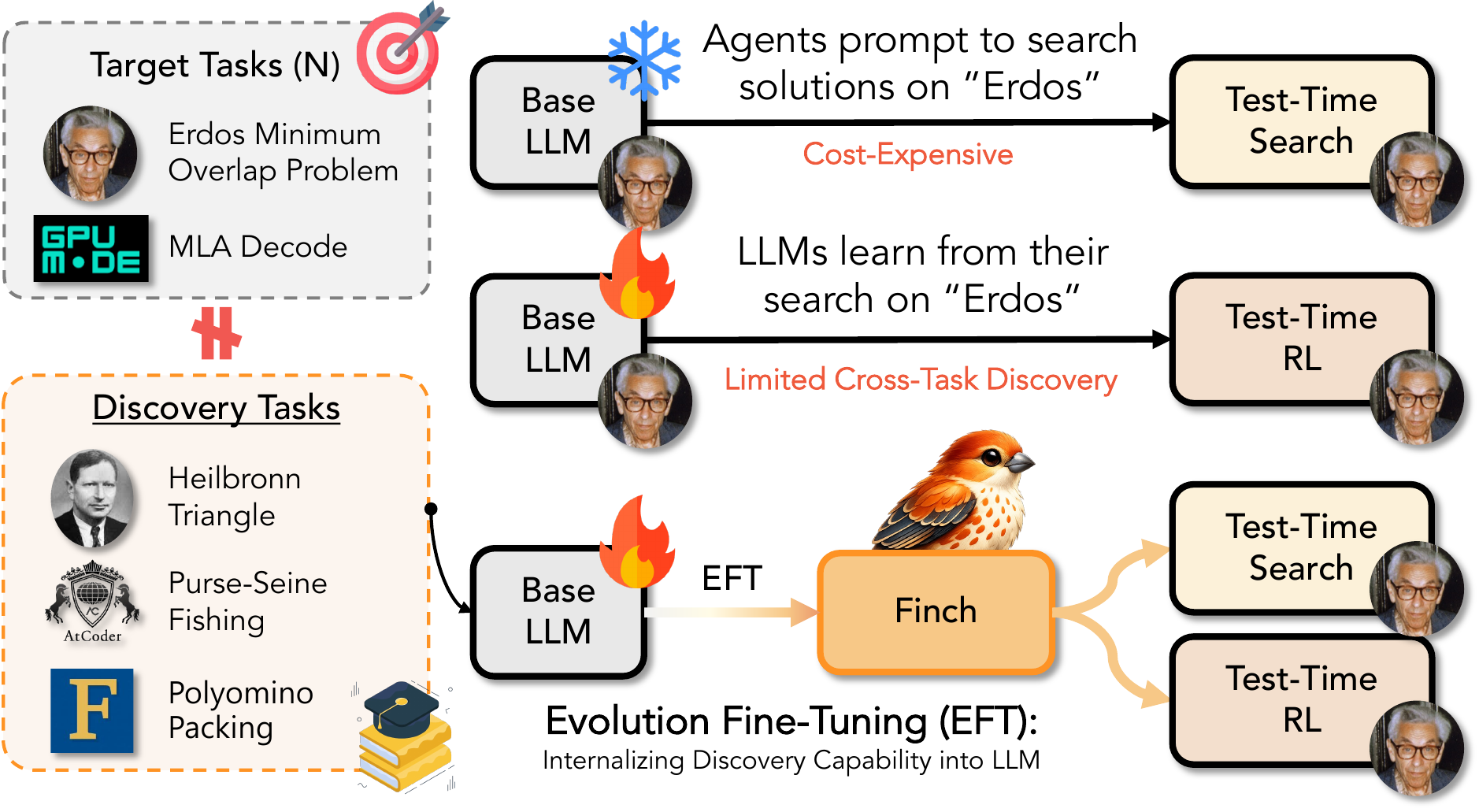
Move discovery skill out of the scaffold and into the model
Test-time search needs an expensive proprietary mutation operator; test-time learning over-fits a single task and throws the strategy away. EFT distills the discovery behavior itself into a small model — which then plugs into either scaffold.
The EFT idea in one picture. Rather than expensive prompting (test-time search) or single-task RL (test-time learning), EFT distills discovery tasks into the model — producing Finch, which then works inside either scaffold with frozen weights or further adaptation.
♻
A mid-training “practice phase”
Instead of rebuilding discovery skill from scratch inside every search run, EFT teaches the LLM how to mutate, what to keep, and when to backtrack — so it practices before deployment rather than solving each new problem from zero.
⚂
Trajectories as supervision
Optimization tasks are NP-hard and lack ground-truth optima, so (problem, answer) pairs are unavailable. EFT instead treats the trajectories of search runs — parent → child transitions with scores — as the training signal.
➚
Orthogonal to the scaffold
An EFT model can serve as a frozen mutation operator inside test-time search, or be further adapted by test-time RL. EFT is a layer beneath both branches, not a replacement for either.
★
Emergent cross-domain transfer
Because it is trained across many domains at once, Finch composes strategies it learned elsewhere when tackling a new problem — behavior the base model never exhibits.
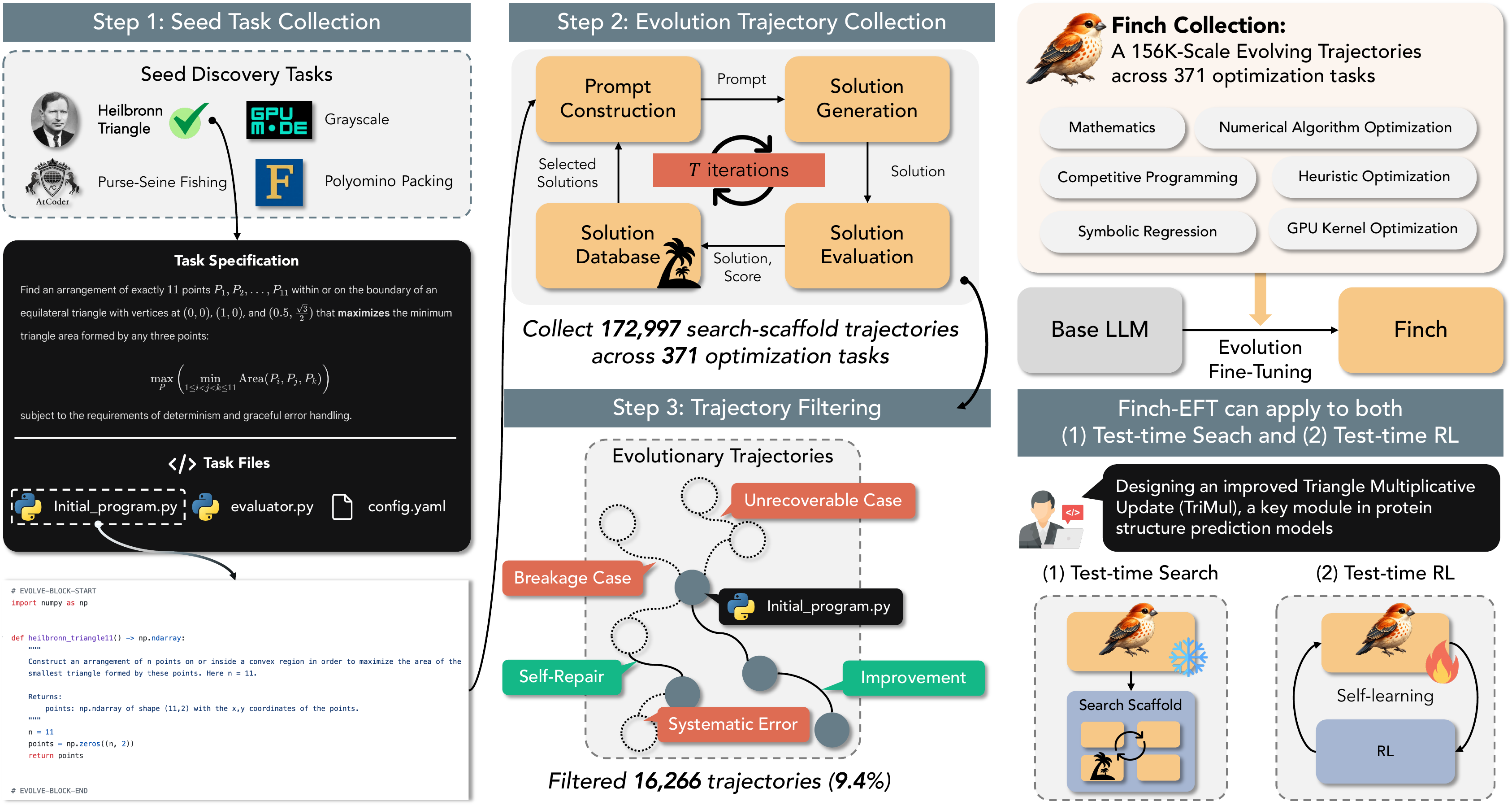
Optimization training data is hard to synthesize, so we source 371 seed tasks from 10 existing benchmarks — each requiring nontrivial search, with a deterministic continuous-score evaluator — and harvest the search itself.
The construction pipeline. Collect seed optimization tasks → run an evolutionary scaffold (OpenEvolve) with a strong teacher mutation operator to harvest parent-to-child trajectories → filter out broken, systematic-error, and overlong cases, yielding ~156K trajectories over 371 tasks.
1
Seed task collection
371 tasks sourced from 10 benchmarks — chosen to require real search, not ground-truth matching, with deterministic scorers.
2
Trajectory collection
OpenEvolve with a Qwen3.5-397B-A17B teacher runs each task under diff-edit and full-rewrite strategies → 172,997 raw trajectories.
3
Filtering & labeling
Remove systematic errors, hard-negative breakages, and overlong inputs (90.6% retained), then label each by score delta.
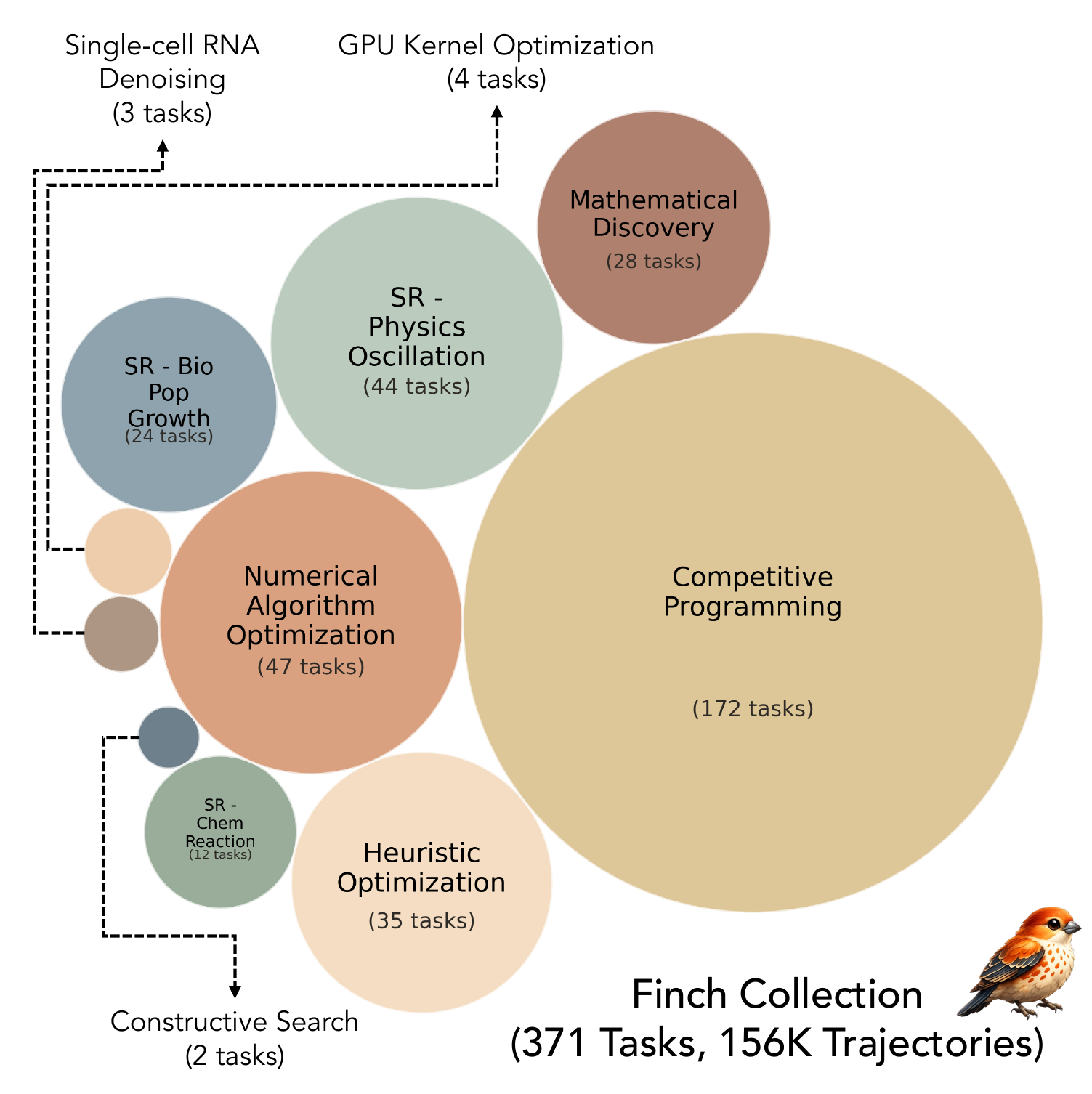
371 tasks across 10 domains. Bubble size shows each group’s task count, led by competitive programming and numerical algorithm optimization.
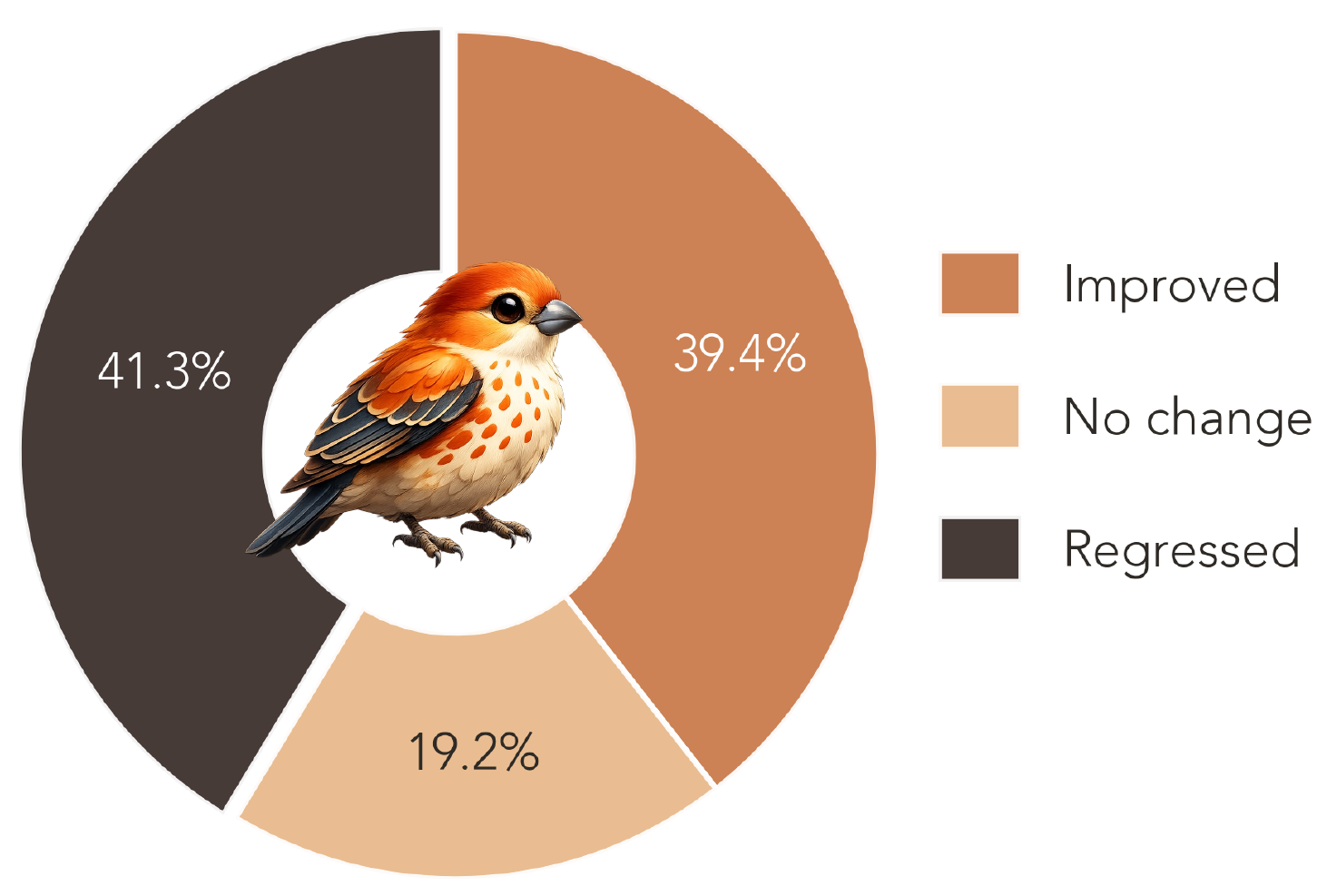
Improvement breakdown. 39.4% of trajectories improve the parent, 19.2% leave it unchanged, 41.3% regress — supplying both imitation and preference (good-vs-bad) signal.
The collection is balanced across languages (68.5% Python / 31.5% C++) and strategies (50.3% diff-edit / 49.7% full-rewrite). We fine-tune the Qwen3.5 (2B/4B/9B) and Qwen3-8B bases via full SFT on improved trajectories from 355 tasks (16 held out), producing the Finch family.
Results
EFT confers cross-task discovery generalization
Used as a mutation operator inside test-time search, Finch beats its base models across 22 held-out tasks — and lets small models rival non-EFT models twice their size.
+10.22%
Average held-out gain
Finch over same-size base models across 22 held-out tasks, with up to +290% on ahc058 and +74% on Transaction.
2× size
Punching above its weight
Finch-4B reaches 0.3865 on Erdős — comparable to Qwen3-8B’s 0.4036 (lower is better), matching a model twice as large.
+14.1%
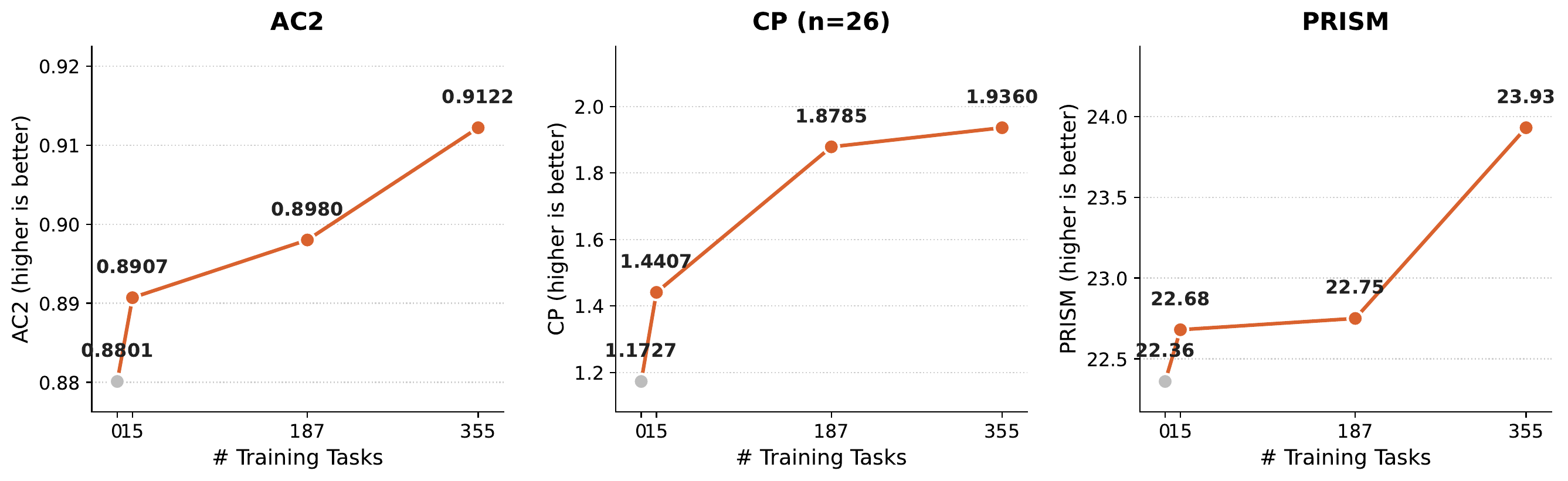
Positive task-scaling
Held-out performance rises steadily as the Finch Collection grows from 15 → 355 training tasks.
Held-out · OpenEvolve
Main results: test-time search
Finch vs. same-size base · 11 held-out metrics
Mathematical Discovery
Algorithm Eng.
System Performance
Model
Erdős↓
AC1↓
AC2↑
CP(26)↑
Hadamard↑
ahc039↑
ahc058↑
EPLB↑
PRISM↑
LLM-SQL↑
Transaction↑
Avg.Δ↑
Best Human
0.380927
1.5097
0.9015
2.634000
0.935673
566,997
847,674,723
0.1265
21.89
0.6920
2724.80
—
Initial Program
0.495056
1.5186
0.8558
0.959764
0.143275
534,850
0
0.1265
21.89
0.6856
2824.86
—
OpenEvolve + Proprietary Models
Claude-Opus-4.6
0.381880
—
—
2.629300
—
—
—
0.1270
26.26
0.7160
3774.00
—
Gemini-3-Pro
—
—
—
2.541400
—
—
—
0.1272
26.24
0.7258
4273.50
—
GPT-5
—
—
—
2.541400
—
—
—
0.1272
26.23
0.7155
4237.30
—
OpenEvolve + Open-source Models
Qwen3.5-2B
0.381737
1.5186
0.8646
1.253056
0.478009
546,078
0
0.1265
21.89
0.6856
2832.86
—
Finch-2B
0.381346
1.5184
0.8920
1.535134
0.400476
545,256
329,359,253
0.1269
22.26
0.6860
2949.85
—
Δ
+0.10%
+0.01%
+3.17%
+22.51%
-16.22%
-0.15%
—
+0.32%
+1.69%
+0.06%
+4.13%
+1.56%
Qwen3.5-4B
0.416924
1.5186
0.8802
1.680787
0.384332
542,077
0
0.1266
21.89
0.6856
2732.24
—
Finch-4B
0.386460
1.5173
0.8933
1.806808
0.146199
551,844
331,466,883
0.1267
22.87
0.6857
4761.90
—
Δ
+7.31%
+0.09%
+1.49%
+7.50%
-61.96%
+1.80%
—
+0.08%
+4.48%
+0.01%
+74.30%
+3.40%
Qwen3-8B
0.403585
1.5177
0.8980
1.797576
0.452330
557,081
0
0.1269
23.81
0.6858
3174.60
—
Finch-8B
0.381236
1.5154
0.9001
1.822617
0.501743
557,168
135,184,684
0.1270
24.70
0.7341
3257.33
—
Δ
+5.54%
+0.15%
+0.23%
+1.39%
+10.92%
+0.02%
—
+0.08%
+3.74%
+7.04%
+2.61%
+3.17%
Qwen3.5-9B
0.385512
1.5186
0.8801
1.172702
0.397184
553,582
134,486,700
0.1269
22.36
0.6858
3584.23
—
Finch-9B
0.381100
1.5141
0.9122
1.936000
0.480585
553,759
525,286,896
0.1265
23.93
0.7024
3636.36
—
Δ
+1.14%
+0.30%
+3.65%
+65.09%
+21.00%
+0.03%
+290.59%
-0.32%
+7.02%
+2.42%
+1.45%
+10.24%
Δ is the relative improvement of Finch over its same-size base, sign-adjusted so positive always means better. Avg. Δ averages the available metrics (ahc058 excluded — its near-zero base inflates the ratio). Finch lifts the average at every scale, up to +10.24% at 9B, and matches strong proprietary operators (Claude-Opus-4.6, Gemini-3-Pro, GPT-5) on several metrics with a far smaller open backbone.
FrontierCS
NP-hard competitive programming
6 UC Berkeley contest problems
Model
P263↑
P301↑
P302↑
P303↑
P304↑
P305↑
Avg.↑
Qwen3.5-2B
0.00
0.00
0.00
0.00
0.00
0.00
0.00
Finch-2B
0.38
1.63
0.12
3.16
0.00
31.43
6.12
Qwen3.5-4B
8.15
20.99
27.07
0.00
0.00
30.89
14.52
Finch-4B
27.44
68.17
24.41
31.79
0.00
40.03
31.97
Qwen3-8B
23.72
44.67
36.78
10.84
0.00
29.23
24.21
Finch-8B
38.12
39.41
36.68
10.84
0.00
22.34
24.56
Qwen3.5-9B
55.09
27.59
35.63
35.54
5.81
35.14
32.46
Finch-9B
86.10
58.78
36.68
34.02
22.11
38.38
46.01
Average score across six NP-hard FrontierCS contest problems. Finch beats its base at every size, reaching 46.01 at 9B (vs. 32.46) — and lets Finch-4B (31.97) outscore the 2×-larger Qwen3-8B base (24.21).
KTO
Offline RL
preference learning on improved + regressed
Model
Erdős↓
AC1↓
AC2↑
CP↑
Best Human
0.380927
1.5097
0.9015
—
Qwen3.5-4B
0.416924
1.5186
0.8802
14.52
Finch-4B
0.386460
1.5173
0.8933
31.97
Finch-4B + KTO
0.381809
1.5151
0.9121
36.30
Qwen3-8B
0.403585
1.5177
0.8980
24.21
Finch-8B
0.381236
1.5154
0.9001
24.56
Finch-8B + KTO
0.381596
1.5089
0.9146
37.30
Further training Finch on improved + regressed trajectories with KTO teaches it to tell good solutions from bad. Finch-8B + KTO surpasses the best human score on AC1 (1.5089) and AC2 (0.9146), and KTO lifts competitive-programming scores to 36–37.
nanodiscover
Online RL (test-time RL)
circle-packing + Erdős
Scaffold
Model
Erdős↓
CP (n=26)↑
CP (n=32)↑
ThetaEvolve
R1-Qwen3-8B
—
2.635983
—
TTT-Discover
GPT-OSS-120B
0.380876
—
—
Qwen3-8B
0.380932
2.635983
2.939572
nanodiscover
Qwen3-8B
0.380956
2.635983
2.939573
Finch-8B
0.380948
2.635983
2.939573
As the policy inside test-time RL (nanodiscover), Finch-8B matches state-of-the-art on both circle-packing tasks (n=26 & n=32) and edges out the Qwen3-8B base on the Erdős problem — EFT serves as mid-training that strengthens what online RL reaches.
Ablation
Scaling effect
15 → 355 training tasks
Positive task-scaling. As the Finch Collection grows from 15 to 355 training tasks, held-out performance rises monotonically on AC2, CP, and PRISM — an average +14.1% improvement, evidence that EFT gains come from task diversity rather than any single task.
Acknowledgement
This research was supported by the “Advanced GPU Utilization Support Program” funded by the Government of the Republic of Korea (Ministry of Science and ICT).
We are grateful to the SkyDiscover team for their valuable feedback on the dataset construction process, the use of the SkyDiscover framework, and the overall direction of this research — in particular, Shu Liu, Shubham Agarwal, and Mert Cemri for their insightful comments and discussions. We also thank the OpenEvolve team, especially Ritik Vijayvergiya and Asankhaya, for their guidance on using the OpenEvolve framework and for their thoughtful comments on this work.
We thank the authors of ALE-Bench, especially Yuki Imajuku, and the AtCoder team for authorizing the public release of the evolutionary search trajectories derived from their CC BY-ND 4.0 licensed dataset.
We further thank Byung‑Kwan Lee for valuable feedback during the early stages of this project.
Citation
BibTeX
If you find Evolution Fine-Tuning or the Finch Collection useful, please cite our work. (arXiv id is added once the preprint is posted.)
@misc{lee2026evolution,
title = {Evolution Fine-Tuning: Learning to Discover Across 371 Optimization Tasks},
author = {Lee, Young-Jun and Kim, Seungone and Kang, Minki and Cheong, Alistair
and Chen, Zerui and Han, Seungho and Jung, Taehee and Kang, Dongyeop},
year = {2026},
eprint = {ARXIV_ID_PLACEHOLDER},
archivePrefix = {arXiv},
primaryClass = {cs.LG},
url = {https://arxiv.org/abs/ARXIV_ID_PLACEHOLDER}
}